
[Sidney Harris cartoon used with permission. Copyright holder: ScienceCartoonsPlus.com.]
Quick, what's 240 plus 240? It's 280, right?
No, obviously not. 40 plus 40 is 80, and 240 times 240 is 280, but 240 plus 240 is only 241.
Take a deep breath and relax. When cryptographers are analyzing the security of cryptographic systems, of course they don't make stupid mistakes such as multiplying numbers that should have been added.
If such an error somehow managed to appear, of course it would immediately be caught by the robust procedures that cryptographers follow to thoroughly review security analyses.
Furthermore, in the context of standardization processes such as the NIST Post-Quantum Cryptography Standardization Project (NISTPQC), of course the review procedures are even more stringent.
The only way for the security claims for modern cryptographic standards to turn out to fail would be because of some unpredictable new discovery revolutionizing the field.
Oops, wait, maybe not. In 2022, NIST announced plans to standardize a particular cryptosystem, Kyber-512. As justification, NIST issued claims regarding the security level of Kyber-512. In 2023, NIST issued a draft standard for Kyber-512.
NIST's underlying calculation of the security level was a severe and indefensible miscalculation. NIST's primary error is exposed in this blog post, and boils down to nonsensically multiplying two costs that should have been added.
How did such a serious error slip past NIST's review process? Do we dismiss this as an isolated incident? Or do we conclude that something is fundamentally broken in the procedures that NIST is following?
Discovering the secret workings of NISTPQC. I filed a FOIA request "NSA, NIST, and post-quantum cryptography" in March 2022. NIST stonewalled, in violation of the law. Civil-rights firm Loevy & Loevy filed a lawsuit on my behalf.
That lawsuit has been gradually revealing secret NIST documents, shedding some light on what was actually going on behind the scenes, including much heavier NSA involvement than indicated by NIST's public narrative. Compare, for example, the following documents:
A public 2014 document says that its author is "Post Quantum Cryptography Team, National Institute of Standards and Technology (NIST), pqc@nist.gov".
A secret 2016 document listed the actual pqc@nist.gov team members, with more NSA people (Nick Gajcowski; David Hubbard; Daniel Kirkwood; Brad Lackey; Laurie Law; John McVey; Mark Motley; Scott Simon; Jerry Solinas; David Tuller) than NIST people. (Another Department of Defense representative on the list was Jacob Farinholt, Naval Surface Warfare Center, US Navy. I'm not sure about Evan Bullock.)
Another secret 2016 document shows that NSA's Scott Simon was scheduled to visit NIST on 12 January 2016.
Another secret 2016 document shows that NIST's "next meeting with the NSA PQC folks" was scheduled for 26 January 2016.
Another secret 2016 document shows that Michael Groves from NSA's UK partner was scheduled to visit NIST on 2 February 2016.
Another secret 2016 document lists Colin Whorlow from NSA's UK partner as someone that NIST visited in 2016, in particular discussing "confidence and developments for each of the primary PQC families".
A public 2020 document says "Engagement with community and stakeholders. This includes feedback we received from many, including the NSA. We keep everyone out of our internal standardization meetings and the decision process. The feedback received (from the NSA) did not change any of our decisions ... NIST encouraged the NSA to provide comments publicly. NIST alone makes the PQC standardization decisions, based on publicly available information, and stands by those decisions".
I filed a new FOIA request in January 2023, after NIST issued its claims regarding the security level of Kyber-512. NIST again stonewalled. Loevy & Loevy has now filed a new lawsuit regarding that FOIA request.
Public material regarding Kyber-512 already shows how NIST multiplied costs that should have been added, how NIST sabotaged public review of this calculation, and how important this calculation was for NIST's narrative of Kyber outperforming NTRU, filling a critical gap left by other steps that NIST took to promote the same narrative. This blog post goes carefully through the details.
Alice and Bob paint a fence. At this point you might be thinking something like this: "Sorry, no, it's not plausible that anyone could have mixed up a formula saying 2x+2y with a formula saying 2x+y, whatever the motivations might have been."
As a starting point for understanding what happened, think about schoolchildren in math class facing a word problem:
There is a fence to paint. Alice would take 120 minutes to paint the fence. Bob would take 240 minutes to paint the fence. How long would it take Alice and Bob to paint the fence together?
The approved answer in school says that Alice paints 1/120 of the fence per minute, and Bob paints 1/240 of the fence per minute, so together they paint 1/120 + 1/240 = 1/80 of the fence per minute, so it takes them 80 minutes to paint the fence.
The real answer could be more complicated because of second-order effects. Probably Alice and Bob working together are getting less tired than Alice or Bob working alone for longer would have. In the opposite direction, maybe there's a slowdown because Alice and Bob enjoy each other's company and pause for a coffee.
Schoolchildren often give answers such as 240 − 120 = 120, or 120 + 240 = 360, or (120 + 240)/2 = 180. These children are just manipulating numbers, not thinking through what the numbers mean.
Two disciplines for catching errors. In later years of education, physics classes teach students a type-checking discipline of tracking units with each number.
Here are examples of calculations following this discipline:
Dividing "1 fence" by "120 min" gives "0.00833 fence/min".
Adding "0.00833 fence/min" to "0.00417 fence/min" gives "0.01250 fence/min".
Taking the reciprocal gives "80.0 min/fence".
The same discipline wouldn't let you add, for example, "1 fence" to "120 min": the units don't match.
This discipline avoids many basic errors. On the other hand, it still allows, e.g., the mistake of adding "120 min" to "240 min" to obtain "360 min".
What catches this mistake is a discipline stronger than tracking units: namely, tracking semantics.
The numbers have meanings. They're quantitative features of real objects. For example, 80 minutes is the total time for Alice and Bob to paint the fence when Alice is painting part of the fence and Bob is painting part of the fence. That's what the question asked us to calculate.
A different question would be the total time for Alice to paint the fence and then for Bob to repaint the same fence. This would be 120 minutes plus 240 minutes.
Yet another question would be the total time for Alice to paint the fence, and then for Bob to wait for the coat of paint to dry, and then for Bob to apply a second coat. Answering this would require more information, namely the waiting time.
All of these questions make sense. They pass type-checking. But their semantics are different.
Alice and Bob tally the costs of an attack. Alice and Bob have finished painting and are now discussing the merits of different encryption systems.
 They'd like to make sure that
breaking whichever system they pick
is at least as hard as searching for an AES-128 key.
They've agreed that searching for an AES-128 key
is slightly above 2140 bit operations.
They'd like to make sure that
breaking whichever system they pick
is at least as hard as searching for an AES-128 key.
They've agreed that searching for an AES-128 key
is slightly above 2140 bit operations.
Alice and Bob are broadcasting their discussion for anyone who's interested. Let's listen to what they're saying:
Alice: "Hmmm, there are a bunch of sources saying that the XYZZY attack algorithm uses 280 iterations to break this particular cryptosystem. It's worrisome that this number is so low. What else do we know about the cost of the attack?"
Bob: "I found a source saying that there are actually extra factors in the iteration count, and estimating that the XYZZY attack uses 295 iterations."
Alice: "Here's another source looking at the details of the computations inside each iteration, and estimating that those computations cost 225 bit operations."
Bob: "There's also a gigantic array being accessed. Here's a source estimating that the memory access inside each iteration is as expensive as 235 bit operations."
Alice: "Okay, let's review. The best estimate available for the total cost of each iteration in the XYZZY attack is around 235 bit operations. A tiny part of that is 225 bit operations for computation. The main cost is the equivalent of 235 bit operations for the memory access."
Bob: "Agreed. Multiplying 295 iterations by 235 bit operations per iteration gives us a total of 2130 bit operations. Doesn't meet the security target."
Alice: "Right, that's a thousand times easier than AES-128 key search. Let's move on to the next cryptosystem."
How to botch the tally of costs. Imagine a government agency that has also been looking at this particular cryptosystem, but with one critical difference: the agency is desperate to say that this cryptosystem is okay.
How does the agency deal with the XYZZY attack?
One answer is to aim for a lower security goal, hyping the cost of carrying out 2130 bit operations. For comparison, Bitcoin mining did only about 2111 bit operations in 2022. ("Only"!)
But let's assume that the agency has promised the world that it will reach at least the AES-128 security level.
What does the agency do?
Here's an idea. For the costs per iteration, instead of adding 225 for computation to 235 for memory access, how about multiplying 225 for computation by 235 for memory access?
The product is 260. Multiplying this by 295 iterations gives 2155, solidly above 2143. Problem solved!
How discipline catches the error. Alice and Bob are correctly tracking the semantics of each number. The agency isn't.
The total attack cost is the number of iterations times the cost per iteration. Each iteration incurs
cost for computation, estimated as 225 bit operations, and
cost for memory access, estimated to be as expensive as 235 bit operations.
The agency's multiplication of these two costs makes no sense, and produces a claimed per-iteration cost that's millions of times larger than the properly estimated per-iteration cost.
This multiplication is so glaringly wrong that it doesn't even pass physics-style type-checking. Specifically, multiplying "225 bitops/iter" by "235 bitops/iter" doesn't give "260 bitops/iter". It gives "260 bitops2/iter2". Multiplying further by "295 iter" doesn't give "2155 bitops"; it gives "2155 bitops2/iter".
Agency desperation strikes back. How can the agency phrase this nonsensical calculation of a severely inflated security estimate in a way that will pass superficial review?
The goal here is for the 155 to sound as if it's simply putting together numbers from existing sources. For example:
Here's a source estimating an iteration count of 295.
Here's a source estimating 225 bit operations per iteration.
Here's a source estimating that accounting for memory multiplies costs by 235.
95 plus 25 plus 35 is 155, solidly above 143.
The deception here is in the third step, the step that leaps from cost 225 per iteration to cost 260 per iteration.
How many readers are going to check the third source and see that it was actually estimating cost 235 per iteration?
Streamlining the marketing. The wrong calculation sounds even simpler if there's a previous source that has already put the 295 and the 225 together:
Here's a source estimating 2120 bit operations.
Here's a source estimating that accounting for memory multiplies costs by 235.
120 plus 35 is 155, solidly above 143.
At this point the agency has completely suppressed any mention of iterations, despite the central role of iterations in the attack and in any competent analysis of the attack.
How many readers are going to check both sources, see that the second source estimates cost 235 per iteration, and see that the iteration count in the first source is far below 2120?
Kyber's limited selection of security levels. You might be thinking something like this: "Okay, sure, I see how it would be possible for a desperate agency to replace cost addition with a nonsensical multiplication, replacing 2130 with a fake 2155, while at the same time making this hard for people to see. But why would anyone have wanted to play this risky game? If Kyber-512 was around 2130, and the target was a little above 2140, why didn't they just bump up the parameters to 10% higher security, something like Kyber-576?"
This is an obvious question given that RSA and ECC and (to take some post-quantum examples) McEliece and NTRU naturally support whatever size you want.
A long, long time ago, I wrote fast software for the NSA/NIST P-224 elliptic curve, and then found a better curve at that security level, namely y2 = x3 + 7530x2 + x mod 2226−5. But then I decided that bumping the size up to 2255−19 would be much more comfortable, so I did.
Kyber is different. You can't just bump up Kyber's parameters to 10% higher security:
Kyber-576 doesn't exist. If you want something stronger than Kyber-512 then you have to increase the "dimension" by 50%, jumping all the way up to Kyber-768.
If you want something stronger than Kyber-768 then you have to jump all the way up to Kyber-1024.
If you want something stronger than Kyber-1024 then, sorry, tough luck.
One of the "unique advantages of Kyber" specifically advertised in the official Kyber documentation is that implementing a "dimension-256 NTT" handles "all parameter sets" for Kyber (emphasis in original). This "NTT" isn't something optional for Kyber implementors; it's baked into the structure of Kyber's public keys and ciphertexts. Using dimensions that aren't multiples of 256 would require changing the core Kyber design.
The same Kyber "advantage" also means that going beyond 1024 would lead to performance issues and, more importantly, security issues surrounding occasional "decryption failures" forced by the prime baked into the NTT. Avoiding this would again require changing the core Kyber design.
For comparison,
NTRU options targeting higher security levels—including
simple proofs that there are no decryption failures—are readily available.
For example, one of the
NTRU Prime
options is sntrup1277.
But let's assume that NIST doesn't care about Kyber's limitations at the high end. Let's instead focus on the low end, specifically on applications that have limited sizes for public keys and/or ciphertexts and thus can't use the highest available security levels.
An application limited to 1KB can't use Kyber-768 (1184-byte public keys, 1088-byte ciphertexts). The highest-security Kyber option for that application is Kyber-512 (800-byte keys, 768-byte ciphertexts).
The same application obtains higher security with NTRU, according to a security-estimation mechanism called "Core-SVP". For example, the application can use
sntrup653 (994-byte keys, 897-byte ciphertexts),
where the Core-SVP security estimate is 2129,
or
NTRU-677 (ntruhps2048677, 931-byte keys, 931-byte ciphertexts),
where Core-SVP is 2145,
while the current version of Kyber-512, starting with the round-3 version from 2020, has Core-SVP just 2118.
Is this "Core-SVP" something I made up to make Kyber look bad? Absolutely not:
Core-SVP is the security-estimation mechanism that was chosen by the Kyber team to estimate security levels in its round-1 and round-2 submissions. The mechanism was introduced by Kyber's predecessor, NewHope.
In 2020, after I expressed skepticism about whether Core-SVP "gets the right ordering of security levels", NIST stated that "we feel that the CoreSVP metric does indicate which lattice schemes are being more and less aggressive in setting their parameters". NIST's official round-2 report in 2020 used Core-SVP for comparisons.
The original definition of Core-SVP assigns 2112 to the round-3 version of Kyber-512. Round-3 Kyber switched to a new definition of Core-SVP that increases Kyber's Core-SVP (without changing anything for NTRU).
This blog post has bigger fish to fry,
so let's blindly accept Kyber's
claim that the new definition is better,
meaning that Kyber-512 has Core-SVP 2118.
That's still clearly worse than the
2129 for sntrup653 and the 2145 for NTRU-677.
It's not that Kyber's competitors
always beat Kyber in size-security tradeoffs.
For example,
if an application instead has a limit of 1184 bytes,
then it can use Kyber-768, which has Core-SVP 2181,
while ntruhps needs 1230 bytes to reach Core-SVP 2179.
But Kyber's competitors often beat Kyber in size-security tradeoffs. Throwing away Kyber-512, leaving just Kyber-768 and Kyber-1024, means that Kyber has nothing as small as the 931 bytes for NTRU-677.
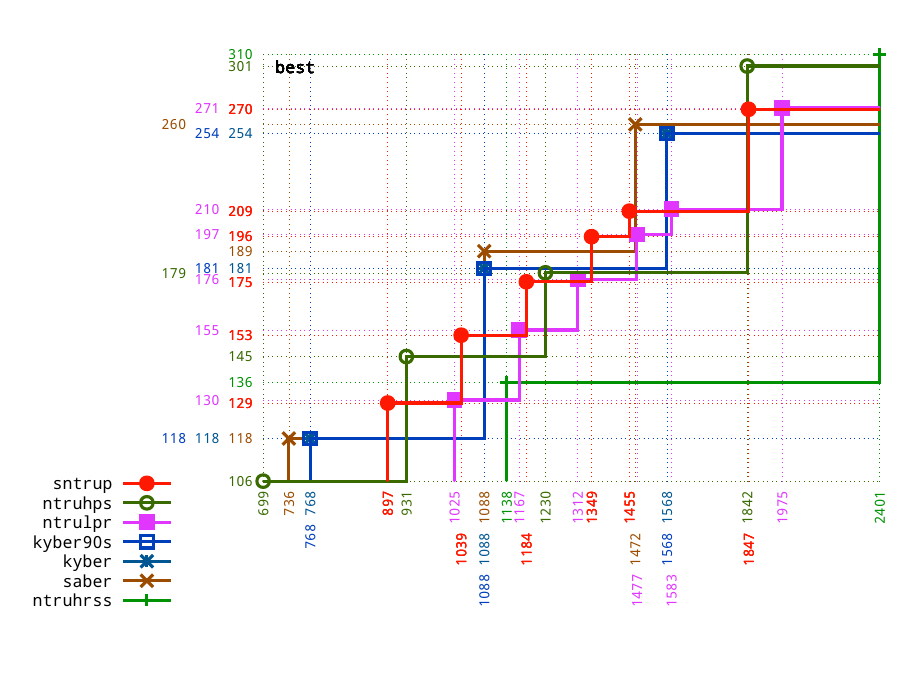 The normal way for scientists to present quantitative tradeoffs is with scatterplots,
such as Figure 3.5 in my 2019 paper
"Visualizing size-security tradeoffs for lattice-based encryption".
The particular scatterplot shown here is
Figure 7.3 in the 2021 paper
"Risks of lattice KEMs"
from the NTRU Prime Risk-Management Team.
The vertical axis is the Core-SVP security estimate,
and the horizontal axis is ciphertext bytes.
The normal way for scientists to present quantitative tradeoffs is with scatterplots,
such as Figure 3.5 in my 2019 paper
"Visualizing size-security tradeoffs for lattice-based encryption".
The particular scatterplot shown here is
Figure 7.3 in the 2021 paper
"Risks of lattice KEMs"
from the NTRU Prime Risk-Management Team.
The vertical axis is the Core-SVP security estimate,
and the horizontal axis is ciphertext bytes.
The scatterplot shows that Kyber has a higher Core-SVP than NTRU for applications with a size limit of, e.g., 768 bytes or 1088 bytes. But NTRU has a higher Core-SVP than Kyber for applications with a size limit of, e.g., 700 bytes or 1024 bytes or 2048 bytes. Kyber has nothing as small as the 699-byte option for NTRU. Kyber also has nothing as strong as the 1842-byte option for NTRU. NTRU is also trivially capable of adding further options between and beyond what's shown in the graph, whereas for Kyber this is more problematic.
Official evaluation criteria for the competition. NIST had issued an official call for post-quantum proposals in 2016. One of the evaluation criteria in the call was as follows:
Assuming good overall security and performance, schemes with greater flexibility will meet the needs of more users than less flexible schemes, and therefore, are preferable.
One of the official examples given for "flexibility" was that it is “straightforward to customize the scheme's parameters to meet a range of security targets and performance goals".
The call proposed five broad security "categories", and said that submitters could specify even more than five parameter sets to demonstrate flexibility:
Submitters may also provide more than one parameter set in the same category, in order to demonstrate how parameters can be tuned to offer better performance or higher security margins.
In 2020, NIST eliminated NewHope. One of the reasons stated in the aforementioned round-2 report was that "KYBER naturally supports a category 3 security strength parameter set, whereas NewHope does not". NewHope offered only NewHope-512 and NewHope-1024.
Imagine Kyber similarly offering only Kyber-768 and Kyber-1024, acknowledging that Kyber-512 doesn't meet the minimum security level specified by NIST. It's then very easy to see how limited Kyber's flexibility is compared to NTRU's broader, denser spectrum of security levels. How, then, would NIST argue that Kyber is the best option?
One answer is that the evaluation criteria say more flexibility is preferable only assuming "good overall security and performance". But how would NIST argue that NTRU doesn't have "good overall security and performance"?
Regarding the security of Kyber and NTRU, NIST's official 2022 selection report says that NIST is "confident in the security that each provides". The report describes MLWE, the problem inside Kyber, as "marginally more convincing" than the problem inside NTRU. There's much more that could and should have been said about the security comparison between Kyber and NTRU:
Kyber's use of modules, despite being portrayed as purely having a (marginal) security benefit, also introduces extra subfields into the cryptosystem structure, creating security risks analogous to the risks of taking extra subfields in pre-quantum DH. Fewer extra subfields appear in NTRU (depending on parameters) than in Kyber. NTRU Prime completely avoids extra subfields.
Kyber's QROM IND-CCA2 proof assuming MLWE hardness is much looser than NTRU's QROM IND-CCA2 proof assuming hardness of the problem inside NTRU. In other words, even under the assumption that MLWE is as strong as the problem inside NTRU, Kyber could be much weaker than NTRU.
NIST could have told people to use NTRU shortly after its deadline for NISTPQC input in 2021. Instead it delayed for three quarters of a year to carry out patent negotiations, and ended up telling people to wait for its Kyber patent license to activate in 2024, giving away three years of user data to attackers. Picking Kyber was doing obvious damage to security given the patent situation.
The situation isn't that NTRU avoids every security risk of Kyber. A careful comparison finds mathematical security risks in both directions. Maybe there's a way to argue that the mathematical security risks for NTRU should be given higher weight than the mathematical security risks for Kyber. But the immediate choice that NIST was facing in 2021 between NTRU and Kyber, assuming that the attackers currently recording user data will have quantum computers in the future, was between
the security risks of NTRU and
the guaranteed security failure of not yet deploying anything.
The call for submissions said "NIST believes it is critical that this process leads to cryptographic standards that can be freely implemented in security technologies and products". Nothing else in the call was labeled as "critical". How could NIST ignore the damage that it was doing in not going ahead with NTRU? NIST knew it didn't have a patent license signed for Kyber yet, let alone an activated patent license.
Anyway, let's get back to the question of how NIST might be able to argue that NTRU doesn't have "good overall security and performance". A report saying that NIST is "confident in the security that each provides" is obviously not claiming that NTRU doesn't have "good overall security". What about performance?
The same selection report admits that
"the overall performance of any of these KEMs
would be acceptable for general-use applications".
If the objective is to use performance differences as a deciding factor
between two acceptable options,
let's see how Kyber would stack up without Kyber-512:
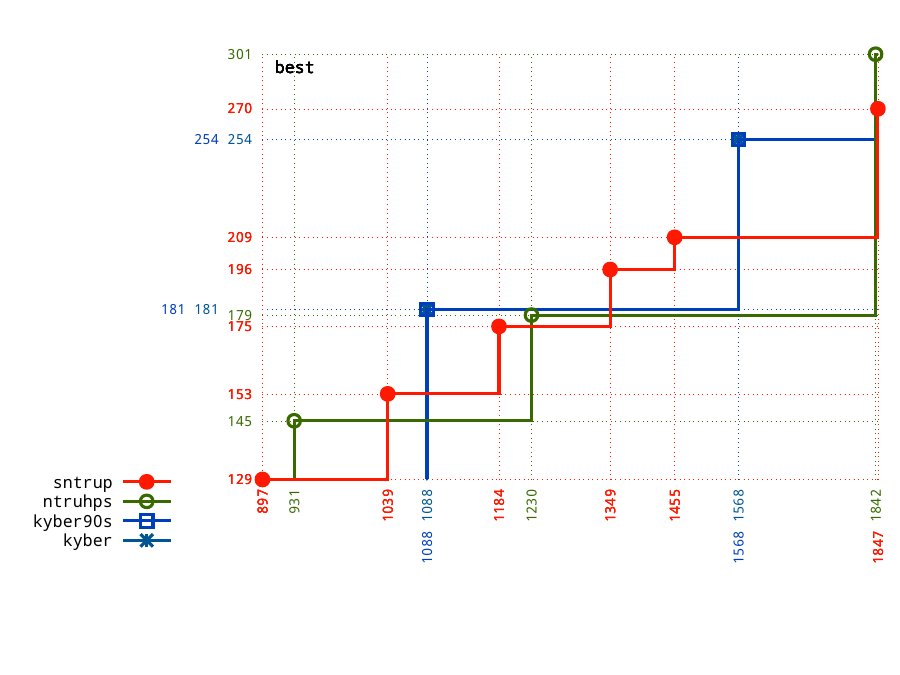
Kyber-768 and Kyber-1024 provide size-security tradeoffs that NTRU doesn't match.
NTRU-677 and NTRU-1229 provide size-security tradeoffs that Kyber doesn't match. Even more options are already implemented for NTRU Prime.
The smallest options are from NTRU, not Kyber.
The highest-security options are from NTRU, not Kyber.
This is a solid case for eliminating Kyber in favor of NTRU, given NIST's declaration that there can be only one.
(If NIST thought that performance differences at this scale matter, and if the best performance comes from Kyber at some security levels and NTRU at other security levels, then why wasn't NIST allowing both? Answer: The movie says there can be only one! STOP ASKING QUESTIONS!)
Tilting the competition, part 1: ignoring NTRU's extra flexibility. Keeping Kyber-512 changes the competition. Having three options, Kyber-512 and Kyber-768 and Kyber-1024, looks a lot better than having just two.
There are four NTRU circles in the first scatterplot above, namely NTRU-509 and NTRU-677 and NTRU-821 and NTRU-1229. But NTRU-821 isn't a winner, and earlier in NISTPQC there wasn't an NTRU-1229.
Wait a minute.
The NTRU literature has always made clear that NTRU supports many more options.
For example,
here's a scatterplot
from John Schanck's 2018 paper
"A comparison of NTRU variants".
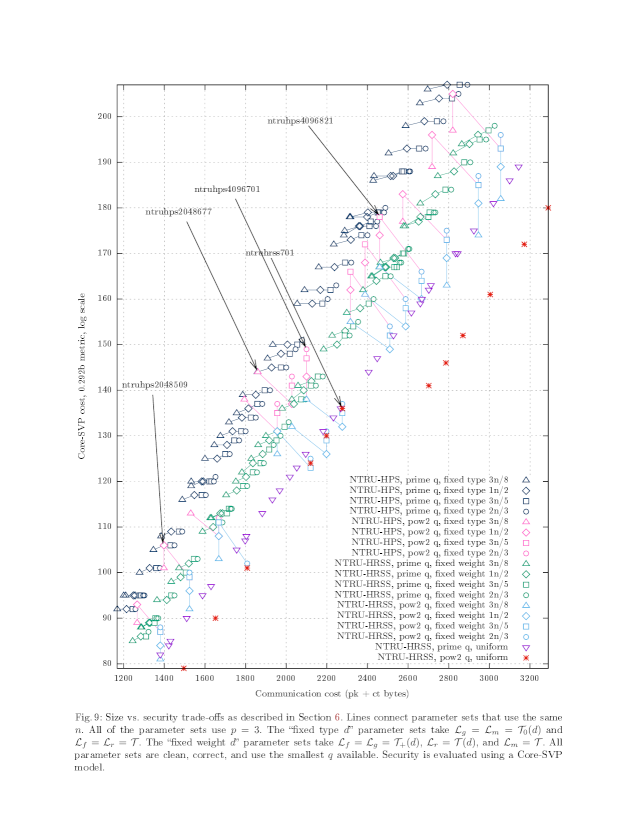 There are a huge number of dots;
each dot is showing another NTRU option.
There are a huge number of dots;
each dot is showing another NTRU option.
One of the bizarre twists in NISTPQC was the following announcement from NIST in 2020: "NIST believes that too many parameter sets make evaluation and analysis more difficult." I asked various questions about this, starting as follows:
How many is "too many"? How did flexibility, which was portrayed as purely positive in the call for proposals, turn into a bad thing for NIST? The call for proposals explicitly allowed multiple parameter sets per category, never suggesting that this would be penalized!
NIST's latest report complains about NewHope's lack of flexibility to use dimensions strictly between 512 and 1024. If a submission team is thinking "Aha, Kyber similarly suffers from its lack of flexibility to target security levels strictly between maybe-2128 and maybe-2192, and we can clearly show this to NIST by selecting parameter sets at several intermediate security levels", then isn't this something NIST should be interested in, rather than discouraging by making submitters worry that this is "too many parameter sets"?
NIST never replied.
Think about what this is like for submitters trying to figure out what to do:
The official evaluation criteria say flexibility is good.
A high-profile submission has just been eliminated, in part for having only two parameter sets.
So, okay, implement more parameter sets to demonstrate flexibility.
But, yikes, NIST is suddenly going out of its way to criticize "too many" parameter sets. They won't say what "too many" means and where this criticism came from.
NTRU Prime
moved up to selecting six sntrup parameter sets
(plus six ntrulpr parameter sets, which, compared to sntrup,
have larger ciphertexts but smaller public keys),
enough that the flexibility advantage over Kyber should have been impossible to ignore.
NIST ignored it.
Tilting the competition, part 2: exaggerating and hyping key-generation costs.
For Intel's recent Golden Cove microarchitecture
(the "performance" cores in Alder Lake CPUs),
https://bench.cr.yp.to
reports that
Kyber-512 takes 25829 cycles for encapsulation and 20847 cycles for decapsulation, while
NTRU-509 takes just 15759 cycles for encapsulation and 25134 cycles for decapsulation.
The total cycle count for handling a ciphertext, the total of encapsulation and decapsulation, is 13% smaller for NTRU-509 than for Kyber-512.
NTRU-509 also beats Kyber-512 in ciphertext size. NTRU-509 is the leftmost dot in the first scatterplot above, meaning smallest ciphertexts.
On the other hand, NTRU-509 takes 112866 cycles for key generation while Kyber-512 takes only 17777 cycles. The total of key generation plus encapsulation plus decapsulation is more than twice as large for NTRU-509 as for Kyber-512.
When some factors favor one option and some factors favor another option, someone objectively searching for the best option will think about what weight to put on each factor. Here are three reasons that a careful performance analysis will put very low weight on Kyber's key-generation speedup:
There's overwhelming evidence that these cycle counts are far less important than byte counts. A useful rule of thumb is that sending or receiving a byte has similar cost to 1000 cycles; see Section 6.6 of the aforementioned paper "Risks of lattice KEMs". Sending a key, receiving a key, sending a ciphertext, and receiving a ciphertext involves thousands of bytes, similar cost to millions of cycles.
All of these KEMs are designed to allow a key to be reused for many ciphertexts. If an application actually cares about the cost of key generation then this reuse is an obvious step to take. NIST's official evaluation criteria already acknowledged the possibility that "applications can cache public keys, or otherwise avoid transmitting them frequently". Many applications are naturally reusing keys in any case.
Even in the extreme case of an application that structurally has to use
a new key for each ciphertext,
there's a trick due to Montgomery that makes NTRU key generation much faster.
Billy Bob Brumley, Ming-Shing Chen, Nicola Tuveri, and I
have a paper
"OpenSSLNTRU: Faster post-quantum TLS key exchange"
at USENIX Security 2022
giving a web-browsing demo on top of TLS 1.3 using sntrup761
with Montgomery's trick for key generation.
We already had the paper and code online in 2021,
before NIST's deadline for input regarding NISTPQC decisions.
In other words: If an average key is used for just 100 ciphertexts then Kyber-512 saving 95089 Golden Cove cycles in key generation is
of similar importance to changing ciphertext size by a fraction of a byte;
6x less important than NTRU-509 saving 5783 cycles per ciphertext; and
not what will happen in applications trying to optimize key-generation time, since in NTRU's case those applications will use Montgomery's trick.
With this in mind, let's look at the "Kyber vs NTRU vs Saber" slide from NIST's March 2022 talk "The beginning of the end: the first NIST PQC standards".
 The eye is immediately drawn to the larger red bars on the right.
NTRU appears in two of the groups of bars,
in both cases with clearly larger bars,
meaning worse performance.
The eye is immediately drawn to the larger red bars on the right.
NTRU appears in two of the groups of bars,
in both cases with clearly larger bars,
meaning worse performance.
The main message NIST is communicating here is that NTRU costs strikingly more than Kyber and Saber. Only a small part of the audience will go to the effort of checking the numbers and seeing how NIST manipulated the choices in its presentation to favor Kyber over NTRU:
The graph gives 100% weight to key generation, utterly failing to account for key reuse.
The graph also utterly fails to account for Montgomery's trick.
The graph does include some recognition of communication costs, but even here NIST couldn't resist tweaking the numbers: "1000*(PK+CT)" counts Alice's cost while omitting Bob's cost.
Regarding the last point: 1000 is just a rule of thumb. NIST could have posted a rationale for a proposal to use 500 and asked for public comments. But it didn't.
NIST's secret October 2021 Kyber-SABER-NTRU comparison claimed, without citation, that I had said 1000*(PK+CT) was reasonable. Compare this to what I had actually written in 2019 about the costs of sending and receiving a ciphertext, after various NTRU Prime documents had given examples backing up the first sentence:
Typically sending or receiving a byte costs at least three orders of magnitude more than a clock cycle. Taking bytes+cycles/1000 for sntrup4591761 gives 1047+45 = 1092 for the sender, 1047+94 = 1141 for the receiver, which is better than 1248 no matter how few cycles you use.
The numbers here account for Alice sending a 1047-byte sntrup4591761 ciphertext
and Bob receiving a 1047-byte ciphertext,
on top of about 45000 Haswell cycles for Alice's enc
and about 94000 cycles for Bob's dec
(which was later sped up a lot,
but this barely matters next to the ciphertext sizes).
See also the more detailed NTRU examples in Section 6.6 of "Risks of lattice KEMs",
filed before NIST's deadline for input at the end of October 2021.
NIST's secret comparison continued by saying "David suggests 2000?", apparently referring to a secret performance comparison in 2020 where NIST used "bandwidth cost of 2000 cycles/byte". Evidently NIST was considering multiple options for this number. Maybe more FOIA results will shed more light on how exactly NIST ended up with a NIST-fabricated option that—quelle surprise!—is better for Kyber.
As for key reuse, NIST might try to defend itself by saying, look, there's a separate PK+CT bandwidth graph on the left, which for these KEMs is visually close to a 2000*CT+enc+dec graph. However:
NIST chose to deemphasize the bandwidth graph by using thinner red bars for it. (See Darrell Huff's classic book "How to lie with statistics", Chapter 5, "The gee-whiz graph".)
The graph isn't invisible, so together the two graphs don't give exactly 100% weight to key-generation time. But a key used for 100 ciphertexts incurs 1 keygen, 100 enc, and 100 dec, meaning only 1% weight for key-generation time, which is very far from the weight conveyed by NIST's slide.
NIST chose to use smaller (and non-log) vertical scales for the bandwidth graph. This further deemphasizes that graph and makes it hard for the audience to notice the size advantage of NTRU-509 (699-byte keys and 699-byte ciphertexts) over Kyber-512 (800-byte keys and 768-byte ciphertexts).
NTRU-509's savings of 170 bytes in key+ciphertext size compared to Kyber-512 is comparable to saving 340000 cycles in total for Alice and Bob. This easily outweighs the cost of NTRU-509 key generation, even in the extreme case of one ciphertext per key, even without Montgomery's trick, even if one rewinds a decade from Alder Lake to Haswell.
In short, NTRU-509's size advantage is more important than Kyber-512's keygen-time advantage. But NIST chose to give more vertical space to Kyber's keygen-time advantage than to NTRU-509's size advantage.
NIST applied a discretization attack to both graphs to conceal the security advantages of the larger NTRU options.
If NIST had provided an honest size-vs.-Core-SVP scatterplot, then readers would have seen that NTRU-677 has much higher Core-SVP than Kyber-512 and much better size than Kyber-768. NIST would never have been able to get away with its claim that NTRU has "somewhat larger public keys and ciphertexts" than Kyber: a scatterplot immediately shows that, no, this depends on the target security level, with NTRU smaller at some security levels and Kyber smaller at others.
Instead NIST started with the options in Core-SVP order and then grouped the options according to "category". Because of this grouping, the options look like they have some arbitrary order within each "category". People looking at the graph have no idea that NTRU's placement farther to the right in each "category" reflects NTRU's higher security levels. A different choice of "category" cutoffs would have reversed the visual comparison.
As for the failure to account for Montgomery's trick, NIST might try to defend itself by saying that the OpenSSLNTRU software focused on NTRU Prime, so NIST's only choice was to presume that there's no speedup for NTRU beyond NTRU Prime. In fact, the OpenSSLNTRU paper had already explained why there will be about a 2x speedup.
Tilting the competition, part 3: concealing the fact that NTRU offers the highest security levels. The official call for submissions in 2016 recommended focusing on "categories 1, 2 and/or 3". See below for a full quote.
The call also recommended that submitters "specify some other level of security that demonstrates the ability of their cryptosystem to scale up beyond category 3". NTRU (and NTRU Prime) did this, specifying parameters across a wide range of security levels. See, e.g., the 2018 scatterplot shown above.
In the aforementioned round-2 report from 2020, NIST suddenly
said that it "strongly encourages the submitters to provide at least one parameter set that meets category 5",
complained that "the NTRU submission lacks a category 5 parameter set proposal" when the costs of memory are ignored, and
complained that NTRU Prime provided "a narrower range of CoreSVP values than other lattice submissions targeting security strengths 1, 3, and 5".
This wasn't following the official evaluation criteria. NIST was retroactively changing "recommend" to "strongly encourage", was retroactively changing "beyond category 3" to "category 5", and was ignoring all of the existing documentation of NTRU's flexibility.
Submissions that provided "category 4", or provided higher security within "category 3", were fully meeting the recommendation in the official evaluation criteria:
Submitters may also provide more than one parameter set in the same category, in order to demonstrate how parameters can be tuned to offer better performance or higher security margins.
NIST recommends that submitters primarily focus on parameters meeting the requirements for categories 1, 2 and/or 3, since these are likely to provide sufficient security for the foreseeable future. To hedge against future breakthroughs in cryptanalysis or computing technology, NIST also recommends that submitters provide at least one parameter set that provides a substantially higher level of security, above category 3. Submitters can try to meet the requirements of categories 4 or 5, or they can specify some other level of security that demonstrates the ability of their cryptosystem to scale up beyond category 3.
But, in 2020, NIST wasn't even trying to follow the official evaluation criteria. It was inventing new evaluation criteria, with no warning, and retroactively applying those criteria to criticize the NTRU and NTRU Prime submissions.
Unsurprisingly, those submissions responded with software for higher security levels:
NTRU responded with reference implementations of NTRU-1229 and NTRU-HRSS-1373. The NTRU team didn't provide optimized implementations (maybe it ran out of time, which is NIST's fault for not having asked for category 5 in the official call four years earlier), but it reported that NTRU-1229 has Core-SVP 2301 and that NTRU-HRSS-1373 has Core-SVP 2310. Both of these are solidly above Kyber-1024's 2254.
NTRU Prime responded with reference and optimized implementations of various options,
such as sntrup1277 and ntrulpr1277,
which have Core-SVP 2270 and 2271 respectively,
again above anything Kyber offers.
(There's a code generator automatically
producing all of the official NTRU Prime implementations;
the generator is
easily extensible to cover further parameter sets.)
After insisting on higher security levels (and adopting Core-SVP) in its 2020 round-2 report, NIST praised NTRU for responding with higher security levels (as measured by Core-SVP) than Kyber, right?
Of course not. NIST concealed the fact that NTRU was offering higher security levels than Kyber:
NIST's big graph doesn't show any NTRU options in the top "category". (The cover story writes itself: The NTRU submission didn't provide optimized software for the new options! Reporting reference speeds would have been unfair! NIST is just trying to protect readers from being misled!)
For readers who go to the effort of looking at the small graph, the discretization attack makes NTRU's higher security levels look just like Kyber's lower security levels.
Readers looking at NIST's graphs are left with the impression that NTRU is less flexible than Kyber and, in particular, has more trouble reaching high security levels. This is exactly the opposite of the facts.
Tilting the competition, part 4: throwing away the highest-performance option. NTRU-1229 and NTRU-HRSS-1373 aren't the only options that NIST excluded from its big graph. Let's again look at the low end, the top-performance end, where NIST chose to exclude NTRU-509.
Optimized NTRU-509 software was already available. If NIST had included NTRU-509 in the big graph then that graph would have shown NTRU-509 as the best performer, better than Kyber-512.
Accounting for key reuse would have further favored NTRU-509. Accounting for Montgomery's trick would have further favored NTRU-509. Upgrading from Haswell would have further favored NTRU-509. Counting 1000 cycles per byte for Alice and for Bob would have further favored NTRU-509.
But NIST simply removed NTRU-509 from the big graph, making NTRU look strictly worse than Kyber in that graph.
NIST went even further in its subsequent report selecting Kyber for standardization: the report didn't show NTRU-509 in any of the figures or tables. The report's descriptions of Kyber's performance were visibly more positive than its descriptions of NTRU's performance, as illustrated by NIST's claim that NTRU has "somewhat larger public keys and ciphertexts" than Kyber.
How does NIST stop people from quickly spotting the errors in this "somewhat larger public keys and ciphertexts" claim?
A discretization attack easily hides the fact that NTRU has smaller sizes than Kyber at intermediate security levels, but it doesn't hide NTRU-509 being smaller than Kyber-512. NIST's narrative also relied on kicking out NTRU-509.
How can NIST justify throwing NTRU-509 away?
The only possible answer is claiming that NTRU-509 doesn't reach the minimum allowed NISTPQC security level, the security level of AES-128. But, at the same time, NIST is including Kyber-512, so NIST is claiming that Kyber-512 does reach the security level of AES-128.
NTRU-509 has Core-SVP 2106, just 6 bits below Kyber-512's original Core-SVP (2112) or 12 bits below Kyber-512's revised Core-SVP (2118). Evidently NIST is claiming that AES-128 is inside this narrow margin: in other words, that NTRU-509 has slightly lower security than AES-128 while Kyber-512 has slightly higher security than AES-128.
 Let's take a moment to admire how spectacularly fragile this is:
Let's take a moment to admire how spectacularly fragile this is:
If some effect slightly increases lattice security levels compared to what NIST is claiming, then NTRU-509 is back in the game, outperforming all of the Kyber options.
If some effect slightly reduces lattice security levels compared to what NIST is claiming, then Kyber-512 is gone, and NTRU-677 outperforms all of the Kyber options.
If security levels are measured in a way that just manages to have Kyber-512 retained while NTRU-509 isn't retained, then NTRU's superior flexibility still provides the highest security level and wins at various intermediate levels, but Kyber wins at other intermediate levels and provides the highest performance level, so putting enough weight on the highest performance level favors Kyber.
See how important it is for Kyber-512 to reach the AES-128 security level? Without that, Kyber is in big trouble: NTRU provides the highest level of security and the highest level of performance and the best flexibility.
The chaos beyond Core-SVP. How is Kyber-512 supposed to reach the AES-128 security level if AES-128 needs more than 2140 bit operations to break while the Core-SVP security estimate for Kyber-512 is only 2118?
This question was briefly addressed in the round-1 Kyber submission in 2017. That submission said that the 2017 version of Kyber-512 had Core-SVP 2112, falling short of the target by 30 bits, but gave a five-line list of reasons that "it seems clear" that Kyber-512 has at least 30 bits more security than Core-SVP indicates.
The round-2 Kyber submission in 2019 made the same claim regarding the 2019 version of Kyber-512. In 2020, I disproved the stated rationale. To summarize:
Kyber's argument that it was gaining security from "the additional rounding noise (the LWR problem, see [13, 8]), i.e. the deterministic, uniformly distributed noise introduced in ciphertexts via [rounding]" was simply wrong. Attackers could freely target Kyber's keys, and the keys didn't have any rounding.
Kyber's argument that it was gaining security from the "additional cost of sieving with asymptotically subexponential complexity" was unfounded and probably wrong: as far as I could tell (and as far as we know today), the actual asymptotics are subexponentially faster than Core-SVP, not subexponentially slower. It was still plausible that the costs for specific sizes such as Kyber-512 were higher than Core-SVP, but this required an analysis that Kyber hadn't carried out.
Kyber's arguments that it was gaining security from "the (polynomial) number of calls to the SVP oracle that are required to solve the MLWE problem" and "the gate count required for one 'operation' " were plausible, but didn't seem to be enough to rescue Kyber-512 without further help.
Kyber's argument that it was gaining security from "the cost of access into exponentially large memory" was plausible as a matter of real-world attack costs. NTRU Prime had already proposed a particular way to quantify this cost.
However, the official call for submissions had asked for a security level of at least 2143 "classical gates" without regard to memory-access costs. So this argument was useless for rescuing Kyber-512: it wasn't what the official evaluation criteria were asking for.
To try to rescue Kyber-512, the round-3 Kyber submission
changed Kyber-512 and (as noted above) redefined Core-SVP to obtain Core-SVP 2118 rather than 2112;
took (without credit) my preliminary analysis of the gaps between Core-SVP and reality;
added further numerical estimates regarding the gaps and the "known unknowns";
concluded that this preliminary analysis gave a 32-bit range of security estimates, specifically 151 bits plus or minus 16 "in either direction"; and
claimed that dropping to 135 wouldn't be "catastrophic, in particular given the massive memory requirements that are ignored in the gate-count metric".
The memory argument again wasn't relevant, given the official evaluation criteria asking for 2143 "classical gates". Kyber-512 wasn't claiming to require 2143 "classical gates" to break; it was claiming some undetermined number between 2135 and 2167.
Various papers then appeared claiming to cut further bits out of lattice security in various ways, such as a 2022 paper reporting an order-of-magnitude speedup from tweaking the "BKZ" layer inside attacks. Many of the papers made the analyses of lattice security even more complicated and even less stable than before. For example, for one line of "dual attacks":
there's an Asiacrypt paper and a paper from Israel's Matzov organization with complicated analyses claiming to reduce Kyber-512's 151 to 137;
but then there's a Crypto paper "Does the dual-sieve attack on learning with errors even work?" giving the impression that, no, this whole line of attacks fails;
but then the actual contents of the Crypto paper are merely saying that there's a "presumably significant" change in the improvements without quantifying the change;
but then there's a new paper "A remark on the independence heuristic in the dual attack" that sounds like it's helping quantify the change;
but that paper still doesn't get all the way to claiming any particular attack cost for Kyber-512;
but then there's another new paper "Rigorous foundations for dual attacks in coding theory" that, for a dual attack against an analogous low-rate decoding problem, says that a "slight modification of this algorithm" avoids the issue raised in the Crypto paper;
but that paper doesn't analyze what the idea means for lattices;
but then there's another new paper "Provable dual attacks on learning with errors" that says it proves the correctness of a simplified dual attack for lattices;
but that paper also doesn't quantify consequences for Kyber-512.
And this is just one small piece of a giant unholy mess that some cryptographers say we should trust.
How, back in 2022, did NIST end up concluding that Kyber-512 is as hard to break as AES-128? Time to look at some quotes. I'll go through the quotes in two parts: first, looking at what NIST said its notion of hardness was; second, going line by line through what NIST said about Kyber-512's security level.
NIST rescuing Kyber-512, part 1: manipulating the qualification criteria. In the call for submissions, it was crystal clear that cryptosystems had to be at least as hard to break as AES-128 in every "potentially relevant" cost metric:
Each category will be defined by a comparatively easy-to-analyze reference primitive, whose security will serve as a floor for a wide variety of metrics that NIST deems potentially relevant to practical security. ...
In order for a cryptosystem to satisfy one of the above security requirements, any attack must require computational resources comparable to or greater than the stated threshold, with respect to all metrics that NIST deems to be potentially relevant to practical security.
(Emphasis in original.)
The call commented on the "classical gates" to break AES-128 etc. Obviously "classical gates" were a "potentially relevant" cost metric.
What exactly is this metric? The literature defines many different gate sets. NIST dodged years of requests to define exactly which gates it was including as "classical gates". NIST's 2022 selection report finally pinned down one part of this, allowing "each one-bit memory read or write" as a cost-1 gate.
Here's an illustration of how important definitions of cost metrics are:
Kyber's security analysis relies on an Asiacrypt 2020 paper for counting the number of "gates" inside the most important attack step inside "primal" attacks.
Tung Chou and I have a new paper "CryptAttackTester: formalizing attack analyses" including an appendix that, for Kyber-512, cuts almost 10 bits out of the "gate" count for the "primary optimisation target" in the Asiacrypt 2020 paper, exploiting the fact that the Asiacrypt 2020 paper counts a memory-access "gate" as cost 1. (The Asiacrypt 2020 paper also relies on this; it's not a typo in that paper.)
The same appendix also disproves the claim that an "optimal" AES-128 key search requires 2143 "gates", but the reduction in AES-128 "gate" counts isn't as large as the reduction in Kyber-512 "gate" counts.
Keep this in mind if you hear people claiming that the costs of lattice attacks have been thoroughly analyzed.
Anyway, being able to access arbitrarily large amounts of memory for cost 1 isn't realistic: the actual costs of data communication grow with distance. But NIST said in 2020 that anyone proposing a replacement metric "must at minimum convince NIST that the metric meets the following criteria", which "seems to us like a fairly tall order":
"The value of the proposed metric can be accurately measured (or at least lower bounded) for all known attacks (accurately mere means at least as accurately as for gate count.)"
"We can be reasonably confident that all known attacks have been optimized with respect to the proposed metric. (at least as confident as we currently are for gate count.)"
"The proposed metric will more accurately reflect the real-world feasibility of implementing attacks with future technology than gate count -- in particular, in cases where gate count underestimates the real-world difficulty of an attack relative to the attacks on AES or SHA3 that define the security strength categories."
"The proposed metric will not replace these underestimates with overestimates."
There have been no announcements on the NISTPQC mailing list of anyone claiming to have met these minimum criteria, never mind the question of whether such a claim could survive public scrutiny.
Recall that NIST excluded NTRU-509 from the figures and tables in its selection report, the report announcing the selection of Kyber over NTRU. If you look for the report's explanation of why NIST excluded NTRU-509, you'll find the following quote:
The submission specification uses both local and non-local cost models for determining the security category of their parameter sets. For a more direct comparison with the other KEM finalists, the assignment of security categories according to the non-local cost model is appropriate. This is what NIST used for NTRU in the figures and tables in this report.
The underlying definition of "local" accounts for long-distance communication costs, whereas "non-local" allows accessing arbitrarily large amounts of memory for free.
Everything I've been describing from NIST above, and more, sounds consistent with the official call for submissions asking for 2143 "classical gates", not counting the costs of memory access:
To try to avoid overestimating security levels, NIST was insisting on counting just bit operations for computation, ignoring the costs of communication.
In response to the round-1 NTRU Prime submission, which provided a detailed rationale for including the costs of memory access, NIST complained in its round-1 report that the submission "uses a cost model for lattice attacks with higher complexity than many of the other lattice-based candidates". (NTRU Prime started reporting Core-SVP in round 2.)
In its round-2 report, as noted above, NIST complained that "the NTRU submission lacks a category 5 parameter set proposal" when memory-access costs are ignored.
In its selection report, NIST kicked out NTRU-509 because NTRU-509's "category 1" claim relied on a "local cost model", i.e., accounting for memory-access costs; see above for the full quote.
With this in mind, consider the fact that NIST was including Kyber-512 in its figures and tables in the same report. This must mean that NIST was claiming that breaking Kyber-512 takes at least 2143 bit operations, without accounting for memory-access costs, right?
Nope. NIST doesn't ask Kyber to meet the same criteria as other submissions.
In November 2022, NIST announced a list of parameter sets that it was "planning" to standardize, including Kyber-512. NIST's announcement avoided claiming that Kyber requires as many "classical gates" to break as AES-128. The announcement specifically acknowledged the possibility of Kyber being "a few bits" below (while omitting the possibility of Kyber being many more bits below):
It is clear that in the gate-count metric it is a very close call and that in this metric the pre-quantum security of Kyber-512 may be a few bits below the one of AES-128.
Instead the announcement relied on accounting for "realistic memory access costs" to claim that Kyber-512 qualified for "category 1":
... the best known attacks against Kyber-512 require huge amounts of memory and the real attack cost will need to take the cost of (access to) memory into account. This cost is not easy to calculate, as it depends on the memory access patterns of the lattice algorithms used for cryptanalysis, as well as the physical properties of the memory hardware. Nonetheless, barring major improvements in cryptanalysis, it seems unlikely that the cost of memory access will ever become small enough to cause Kyber-512 to fall below category 1 security, in realistic models of security that take these costs into account. We acknowledge there can be different views on our current view to include Kyber-512.
As a point of clarification: in this email, we refer to parameter sets based on the claimed security strength category where those parameter sets are most recently specified, irrespective of whether those parameter sets actually meet their claimed security level. That said, our current assessment is that, when realistic memory access costs of known attacks are taken into account, all the parameter sets we plan to standardize do, in fact, meet their claimed security strength categories.
(Emphasis added.)
 So NIST used a "non-local" free-memory metric to kick out NTRU-509,
but used a memory-access-is-expensive metric
to claim that Kyber-512 qualifies for "category 1".
Can anyone tell me how these two things make sense together?
So NIST used a "non-local" free-memory metric to kick out NTRU-509,
but used a memory-access-is-expensive metric
to claim that Kyber-512 qualifies for "category 1".
Can anyone tell me how these two things make sense together?
(As a side note, NIST subsequently stated that its 2022 selection report was merely reflecting "the submitters' claimed security categories" and that the report was making no "assertions about whether or not the parameter sets actually provided the claimed level of security". How does NIST reconcile this with the report kicking out NTRU-509 while keeping Kyber-512? Both of those submissions were claiming to achieve "category 1" given memory-access costs.)
For anyone who cares about reviewability of security analyses, NIST's sudden switch to accounting for Kyber's memory-access costs should be setting off alarm bells.
None of the official Kyber security analyses had tried to quantify the effects of memory on security levels. The Kyber documentation had merely pointed at memory as supposedly saving the day in case there weren't enough "gates".
In the absence of an analysis, how exactly was NIST concluding that memory-access costs were enough to close the gap?
NIST rescuing Kyber-512, part 2: NIST's botched security analysis. In early December 2022, I asked how NIST was arriving at its conclusion that Kyber-512 was as hard to break as AES-128.
NIST followed up with an explanation on 7 December 2022. I'll refer to this explanation as "NIST's botched security analysis of Kyber-512"; for brevity, "NISTBS".
One of the complications in NISTBS is that it considers a large space of scenarios, with analysis steps mixed into comments on the likelihood of each scenario. Even worse, NISTBS doesn't give any confirming end-to-end examples of the tallies obtained in each particular scenario. So a security reviewer has to trace carefully through each step of NISTBS.
Here's one example of a scenario from within the space that NISTBS specifies. I'll call this "scenario X" for future reference. Scenario X makes the following three assumptions:
Assume accuracy of 2137 from the most recent attack paper taken into account (Matzov) regarding the number of "gates". (This is a number specifically mentioned in NISTBS as a starting point; see below. NISTBS also considers the more complicated possibility of this estimate being invalid.)
Assume this isn't affected by the "known unknowns". (This is a possibility specifically mentioned in NISTBS; see below. NISTBS also considers the more complicated possibility of the security level being affected by the "known unknowns".)
Assume accuracy of the RAM-cost model in the NTRU Prime documentation. (This is one of two sources that NISTBS repeatedly points to and calculates numbers on the basis of. NISTBS also considers other possibilities for the RAM cost.)
Obviously the quantitative conclusions of NISTBS vary depending on the exact assumptions. Considering scenario X is simpler than considering the full space of scenarios. I'll use scenario X as an example below.
Without further ado, here's every line of NISTBS, NIST's botched security analysis of Kyber-512.
We can elaborate a little bit further on our reasoning leading to our current assessment that Kyber512 likely meets NIST category I (similar considerations apply to the other parameter sets we plan to standardize for lattice-based schemes.)
This is a preliminary statement regarding the importance of the calculations at hand. See below for the calculations.
That said, beyond this message, we don’t think further elaboration of our current position will be helpful. While we did consult among ourselves and with the Kyber team,
I filed a formal complaint in December 2022 regarding NIST's lack of transparency for its investigation of Kyber-512's security level. As noted above, I filed a new FOIA request in January 2023.
it’s basically just our considered opinion based on the same publicly available information everyone else has access to.
This is not true. NISTBS starts from, e.g., the Matzov paper's 2137 estimate for "gates", but then goes beyond this in quantifying the impact of memory costs, something the Matzov paper definitely did not do. What we'll see later is how NISTBS botches its own calculations starting from the Matzov number.
The point of this thread is to seek a broader range of perspectives on whether our current plan to standardize Kyber512 is a good one, and a long back and forth between us and a single researcher does not serve that purpose.
Public review of NIST's security evaluations requires transparency and clarity regarding those evaluations. It is not appropriate for NIST to be asking for a range of perspectives while concealing information. An open and transparent process would involve less "back and forth" than the process that NIST chose.
Here's how we see the situation: In April this year, “Report on the Security of LWE” was published by MATZOV (https://zenodo.org/record/6412487#.Y4-V53bMKUk), describing an attack, assessed in the RAM model to bring some parameter sets, including Kyber512, slightly below their claimed security strength categories.
This is the most recent attack paper mentioned in NISTBS. That's why my definition of scenario X says "the most recent attack paper taken into account (Matzov)".
It's surprising that NISTBS doesn't mention any of the newer attack papers. NIST had hypothesized that there are no "major improvements in cryptanalysis" (see full quote above), but this doesn't justify ignoring the improvements that have already been published!
Anyway, given that NISTBS is calculating security levels starting from the Matzov paper, let's look carefully at those calculations.
"Assessed in the RAM model" appears to be referring to the Matzov paper counting the number of "gates". As a side note, "the" RAM model is ambiguous; the literature defines many different RAM models, and many different sets of "gates", as noted above.
In particular, the report estimates the cost of attacking Kyber512 using a classical lattice attack to be 2137 bit operations, which is less than the approximately 2143 bit operations required to classically attack AES-128.
NISTBS takes this 137 as the foundation of various calculations below.
This doesn't mean NISTBS is saying Kyber-512 is broken in 2137 "gates". NISTBS is saying that Matzov estimated 137, and then NISTBS is calculating various consequences of the 137. If the 137 is inaccurate then the details of the NISTBS calculations (see below) go up or down accordingly.
For purposes of putting together the sources available, the simplest case to consider is that 2137 accurately counts the number of "gates". Scenario X explicitly assumes this.
However, like previous lattice attacks, the MATZOV attack is based on sieving techniques, which require a large amount of (apparently unstructured) access to a very large memory.
In announcing its plans to standardize Kyber-512, NIST had said that "the best known attacks against Kyber-512 require huge amounts of memory"; here NISTBS is reiterating this.
The RAM model ignores the cost of this memory access,
Indeed, the "gate" counts in question ignore the cost of memory access.
and while the science of comparing the cost of memory access to other costs involved in a large cryptanalytic attack is not as mature as we would like, it seems overwhelmingly likely that, in any realistic accounting of memory access costs, these will significantly exceed the costs that are assessed by the RAM model for lattice sieving.
Here are three obvious examples of quantitative questions raised by this part of NISTBS. Quantification is essential for cryptographic security review.
First, what exactly does "significantly" mean in this context?
Second, how does NISTBS reach its "overwhelmingly likely ... significantly exceed" conclusion?
Third, how does NISTBS get from "significantly exceed" to its conclusion that having Kyber-512 fall short of AES-128 is "unlikely"? (Assuming no "major improvements in cryptanalysis".)
NISTBS does eventually get to some quantified calculations; see below.
The largest practical implementation of sieving techniques we know of, described in detail in “Advanced Lattice Sieving on GPUs, with Tensor Cores” by Ducas, Stevens, and van Woerden (https://eprint.iacr.org/2021/141), was forced by memory access limitations, to adopt settings for bucket size, that would be suboptimal according to the RAM model.
Something else unclear from this part of NISTBS is whether "bucket size ... suboptimal" is supposed to imply NIST's "significantly" claim regarding "costs", and, from there, NIST's claim that it's "unlikely" for Kyber-512 to be easier to break than AES-128.
It should be noted that, increasing the scale of the instances being attacked to near cryptographic scale would probably require extensive hardware optimization, e.g. by using special purpose ASICs, and these techniques, being generally acknowledged to be less effective against memory-intensive tasks, would likely make memory access even more of a bottleneck.
Qualitatively, this is a reasonable summary of what the literature on point is saying. However, at this point the reader still doesn't know how NISTBS gets from this to the claim that Kyber-512 is "unlikely" to be below the AES-128 security level.
Additionally,
This is where NISTBS transitions into quantification.
While the Kyber, Dilithium, and Falcon teams did not give a quantitative assessment of the practical cost of memory access during sieving against cryptographic parameters, assessments by the NTRU and NTRUprime teams gave estimates that would suggest the cost of sieving against category 1 parameters, in models that account for the cost of memory access, is something like 20 to 40 bits of security more than would be suggested by the RAM model.
Finally some numbers to work with! See below for how NISTBS uses these numbers.
As a side note, NIST seems to have very low confidence in the numbers it's citing, saying not just "estimates" but also "suggest" and "something like". But the question I want to focus on here is not how confident NIST is in the sources that it cites. The question is simply what security level NISTBS is calculating for Kyber-512 starting from the sources it cites.
Scenario X explicitly assumes accuracy of one of the two sources that NISTBS cites, specifically NTRU Prime. In context, this choice of source is favorable to Kyber: NISTBS points to NTRU Prime as giving Kyber a 40-bit bonus, and points to NTRU as giving Kyber only a 20-bit bonus.
(For NTRU’s estimates see section 6.3 of the round 3 specification document available at https://ntru.org/index.shtml . For NTRUprime’s estimates see section 6.11 of https://ntruprime.cr.yp.to/nist/ntruprime-20201007.pdf .
Scenario X specifically assumes "accuracy of the RAM-cost model in the NTRU Prime documentation", one of the two sources that NISTBS relies upon for its quantification. See below for the numbers that NISTBS obtains from this source.
The Kyber spec (available at https://pq-crystals.org/kyber/data/kyber-specification-round3-20210804.pdf) discusses, but does not quantify, memory access costs in section 5.3 (Q6))
Indeed, what's cited here doesn't quantify this. So let's keep going with the numbers that NISTBS obtains from other sources.
Taking Matzov's estimates of the attack cost to be accurate,
This is exactly what scenario X is assuming. Of course, NISTBS also considers other possibilities, but, as an illustrative example, let's follow through what NISTBS obtains from this assumption.
only 6 bits of security from memory access costs are required for Kyber512 to meet category 1,
Indeed, 137 is "only" 6 bits short of the 143 goal. NIST wants to find 6 bits of security that it can credit to Kyber-512, plus so much security margin that it can claim not to be worried about the "known unknowns" etc. The point of NISTBS is to argue that the costs of memory do the job.
so in this case Kyber512 would meet category 1 even if the NTRU and NTRUprime submission significantly overestimate the cost of memory access in lattice sieving algorithms.
Here NIST is finding more than its desired 6 bits of security, by giving Kyber the aforementioned "20 to 40 bits" coming from "assessments by the NTRU and NTRUprime teams" of the extra costs coming from memory access.
For example, if NTRU says 20 and if this is accurate, then NISTBS is calculating a security level of 137+20 = 157, safely above 143. (Again, this is explicitly assuming accuracy of the 137 in the first place.)
As another example, if NTRU Prime says 40 and if this is accurate, then NISTBS is calculating a security level of 137+40 = 177, even farther above 143. (Once again assuming accuracy of the 137.)
See how simple this calculation is? NISTBS points to its sources as saying that there are actually "20 to 40 bits of security more than would be suggested by the RAM model" (in NIST's words). So NISTBS adds 20 or 40 to Matzov's 137, giving 157 or 177.
NIST says that even if those sources have "significantly" overestimated the memory-access cost then Kyber-512 is still okay. To figure out what NIST means by "significant" here, simply work backwards from NIST's desired conclusion: if "20 bits" is overestimated by as many as 14 bits, then that still leaves 20−14 bits, covering the desired 6 bits. Anyway, Scenario X simply assumes accuracy of the NTRU Prime RAM-cost model.
Further, since about 5 of the 14 claimed bits of security by Matzov involved speedups to local computations in AllPairSearch (as described by section 6 of the MATZOV paper), it is likely that Kyber512 would not be brought below category 1 by the MATZOV attack, as long as state of the art lattice cryptanalyses prior to the MATZOV paper were bottlenecked by memory at all.
It's of course correct that if there's a bottleneck then speeding up computations outside the bottleneck has little impact. See below for how NIST seems to be using this to claim even more security.
However, we acknowledge there is some additional uncertainty in the exact complexity of the MATZOV attack (and all other sieving-based lattice attacks) due to the known-unknowns Dan alludes to (described with quantitative estimates in section 5.3 of the Kyber spec.)
Three reasons that it might be possible to beat Matzov's 2137 "gates" are (1) inaccuracies in Matzov's analysis (of course, these could also point the other way), (2) missing optimizations covered by the "known unknowns", and (3) missing optimizations beyond the "known unknowns".
Here NIST is pointing to #2. As a side note, it's disturbing to not see NIST accounting for #1 and #3. NIST explicitly assumed that there are no "major" improvements in cryptanalysis; but some of its scenarios have Kyber with very few bits of security margin, and closing those wouldn't require "major" improvements.
Scenario X skips this complication: it explicitly assumes that the 137 is accurate, and that there are no improvements from the "known unknowns".
Nonetheless, even taking the most paranoid values for these known-unknowns (16 bits of security loss),
This is what the Kyber documentation says is the worst case, yes.
the cost of memory access and/or algorithmically making memory access local, would still need to be less than what both the NTRU and NTRUPrime submissions assume.
I found this puzzling when I first saw it: if we take 137, and then subtract a hypothesized 16, then we need to find 22 bits, which is less than the 40 that NISTBS mentioned but not less than the 20. What's going on?
The best explanation I could come up with is that NIST thinks the 16 overlap the 5 bits that NISTBS mentioned above from Matzov, so NIST is actually taking 137−16+5, meaning that NIST has to find only 17 bits, and then the 20 that NISTBS attributes to NTRU is enough (at least if we disregard the uncertainties conveyed by "estimate" and "suggest" and "something like").
Again, Scenario X simply assumes that the 137 is accurate, with no speedups from the "known unknowns", so this complication doesn't arise for that scenario.
The low end estimate of approximately 20 bits (from the NTRU submission) is based on a conjecture by Ducas that a fully local implementation of the BGJ1 sieving algorithm is possible.
Here NIST is pointing to a reason to ask whether the NTRU model is too low. Scenario X explicitly takes the NTRU Prime model, which doesn't trigger this particular issue.
So, in the case that all known-unknowns take on the most paranoid values, this would either require a sieving algorithm with local memory access that is much better than any such published algorithm, and in fact better than any that has been conjectured (at least as far as we are aware),
This is summarizing the NISTBS calculations from the perspective of what algorithmic improvements would be required to break NIST's conclusions. This isn't relevant to scenario X.
or it would require the approximately 40 bits of additional security quoted as the "real cost of memory access" by the NTRUprime submission to be a massive overestimate.
This is summarizing the NISTBS calculations from the perspective of what modeling errors would be required to break NIST's conclusions.
It's concerning to observe deviations between what NISTBS attributes to its source here and what the source actually says. For example, the source says that it's estimating the cost of memory access, whereas NIST incorrectly makes it sound as if the source is mislabeling an estimate as a fact. Furthermore, contrary to what NISTBS's "quoted as" claim leads readers to believe, the "40 bits" that NISTBS claims as memory overhead is not a quote from what the source says on this topic.
Presumably NIST obtained 40 in the following easy way: look at the
security-level table on page 103 of the source; observe that pre-quantum
sieving for sntrup653 at the top is listed as 169 and 129 for "real"
and "free" respectively; subtract the 129 from the 169.
In any event, a lot of things would have to go wrong simultaneously to push the real-world classical cost of known attacks against Kyber512 below category 1, which is why we don't think it's terribly likely.
This is going beyond the per-scenario calculations into an overall probability conclusion.
As a final note, known quantum speedups for lattice sieving are much less effective than Grover’s algorithm for brute force key search, so in the likely scenario where the limiting attack on AES128 is Grover’s algorithm, this would further increase the security margin of Kyber512 over AES128 in practice.
This is yet another complication, and one with several unquantified steps. It's also blatantly inconsistent with earlier comments from NIST on the impact of Grover's algorithm.
For example, in email dated 11 Sep 2017 13:48:59 +0000 to pqc-forum@nist.gov (before the list moved to Google), NIST wrote that "even if we assume the sort of quantum technology often suggested to be possible in 15 years (e.g. ~1GW power requirement and a few hours to factor a 2048 bit number), current technology can still do brute force search cheaper than Grover’s algorithm". Where are the numbers backing up NIST's new claim that Grover's algorithm is "likely" the top threat?
Surely NIST agrees that pre-quantum metrics are at least "potentially" relevant to the practical security of Kyber-512. Consequently, under the official evaluation criteria, NIST can't use post-quantum metrics as a way to rescue Kyber-512 if Kyber-512 is easier to break than AES-128 in the pre-quantum metrics.
I'll focus below on how NISTBS botched its calculation of the pre-quantum Kyber-512 security level.
What the underlying numbers actually mean. Core-SVP is a rough estimate for the number of iterations in a particular type of lattice attack. Each iteration involves large-scale memory access and computation.
Let's look at how the latest versions of the documentation for two submissions, NTRU Prime and Kyber, convert their estimates for the number of iterations into larger security-level estimates. (Note that both of the documents in question are from 2020, so the numbers don't include subsequent attack improvements.)
NTRU Prime focuses on the cost of memory access. In particular, for the important task of sorting N small items, a two-dimensional circuit of area essentially N needs time essentially N1/2, whereas a circuit of the same area running for the same time can carry out essentially N3/2 bit operations.
To put these two types of costs on the same scale, the NTRU Prime documentation estimates "the cost of each access to a bit within N bits of memory as the cost of N0.5/25 bit operations", and explains how the 25 comes from analyzing energy numbers reported by Intel.
As a concrete example:
The NTRU Prime documentation reports Core-SVP 2129 for sntrup653,
meaning a rough estimate of 2129 iterations.
The documentation also reports a rough estimate
that memory accesses cost, in total,
the equivalent of 2169 bit operations for sntrup653.
This comes from combining
the N0.5/25 formula with estimates for N, for the number of iterations,
and for the number of bits accessed inside each iteration.
For comparison, recall that Kyber-512 says Core-SVP 2118. A rough estimate for the cost of memory accesses in this Kyber-512 attack is the equivalent of 2154 bit operations.
This might sound similar to the Kyber documentation estimating 2151 bit operations ("gates"). But the 2151 estimate in the Kyber documentation isn't an estimate of the bit-operation equivalent of memory access. It's ignoring memory access. It's instead considering the number of bit operations used inside the attack's computations, and estimating that this number is somewhere between 2135 and 2167, given the "known unknowns".
Agency desperation, revisited. With the meaning of the numbers in mind, let's briefly summarize how NISTBS tries to use computations and memory to push up the claimed security level of Kyber-512:
Indeed, Core-SVP estimates 2118 iterations, at least with the round-3 Kyber redefinition of Core-SVP.
Yes, the Kyber-512 documentation has a preliminary estimate of 2151 bit operations.
Will it? Quantification needed.
This is where NISTBS goes horribly wrong.
The calculation here doesn't even pass basic type-checking.
Yes, there's a 240 in NTRU Prime for sntrup653,
but that's 240 bitops/iter.
Multiplying this by Matzov's bitops,
and portraying the result as bitops,
is nonsense from NIST.
Whatever the cost is for computation per iteration, you have to add that to the cost for memory access per iteration. Multiplying is wrong.
In the typical case of both numbers being considerably above 1, multiplying the numbers—which is exactly what NISTBS is doing when it says "40 bits of security more than would be suggested by the RAM model" and "40 bits of additional security"—gives an embarrassing, indefensible overestimate of attack costs.
To finish this NISTBS recap, let's briefly summarize the happy conclusions that NISTBS draws:
Look at how much security margin we have here! The critical point is that, starting from 137, "only 6 bits of security from memory access costs are required for Kyber512 to meet category 1" (NIST's words). So we don't have to worry about a few bits here and there, such as the possibility of 137 being too high.
We can even get away with replacing 40 bits from NTRU Prime with an attacker-optimistic 20 bits of security from NTRU, since that gives 157 bits of security. Still way above 143! Surely we aren't going to lose all 16 bits from the "known unknowns".
To summarize, "a lot of things would have to go wrong simultaneously to push the real-world classical cost of known attacks against Kyber512 below category 1, which is why we don't think it's terribly likely" (NIST's words).
Yeah, sounds great, except that it's all based on a botched calculation.
How easy it is to catch the error. This blog post is aimed at people who want to understand the whole picture of what's going on here. But imagine that you're looking at NISTBS without knowing any of this. How quickly can you see that NISTBS is wrong?
I think the fastest answer is the following simple sanity check. If
Kyber estimates that the computations in breaking Kyber-512 cost between 2135 and 2167 bit operations, and
NTRU Prime estimates that the memory accesses in breaking sntrup653
(which seems harder to break than Kyber-512)
cost the equivalent of 2169 bit operations,
and
attacks then improve by a factor 214,
how can NIST end up estimating that breaking Kyber-512 costs 2177 bit operations?
This doesn't tell you where NIST went wrong, but there's a more basic trick that works for that. See where NISTBS is claiming that the NTRU Prime documentation estimates "40 bits of security more than would be suggested by the RAM model" (NIST's words), without giving a full quote from the NTRU Prime documentation?
I'm one of the NTRU Prime submitters. I already knew that this NISTBS claim was false: it's misattributing NIST's wishful thinking to the NTRU Prime documentation. But say you're reading this claim without knowing in advance that it's false. How do you figure out that it's false?
Here's a hard answer and an easy answer:
Hard answer: Follow NISTBS's pointer to Section 6.11 of the documentation. That section starts on page 68, ends on page 70, doesn't say "40", and doesn't say "the RAM model". You can read through all the formulas and comments, try to match it up to the NISTBS claim, and see that nothing matches.
Easy answer: As soon as you observe that this citation is hard to check, simply ask for clarification regarding what exactly the citation is referring to. Honest authors will be happy to clarify.
As a followup, let's imagine that NIST responds by saying "We calculated the 40 by subtracting 129 from 169 on the top row of Table 2". NIST is then implicitly claiming that the 129 is an example of calculating security in "the RAM model". How do you figure out that this implicit claim is false?
This followup similarly has a hard answer and an easy answer:
Hard answer: Read through enough material about what NIST calls "the RAM model" to see that this doesn't match the definition of the 129 in the source document.
Easy answer: Simply ask for clarification of what exactly the rest of the citation, the part attributing something about "the RAM model" to the NTRU Prime documentation, is referring to. Honest authors will again be happy to clarify.
Asking questions
is the normal scientific process
for rapidly reaching clarity—and rapidly fixing errors.
For the particular error at hand,
it takes very few rounds to pinpoint the discrepancy:
the 2129 in the source document for sntrup653 is Core-SVP,
not a gate count in what NIST calls "the RAM model".
Of course, this clarification process doesn't work when an agency decides to dodge clarification questions, for example because it doesn't want errors to be fixed.
The research that would be needed for a correct calculation. To fix NIST's calculation, one needs to carefully distinguish two different effects:
Kyber-512's preliminary estimate of security being 33 bits above Core-SVP (151 vs. 118) comes partially from estimating the number of bit operations inside the computations in an iteration inside a "primal" attack; see the Asiacrypt 2020 paper mentioned above. The cost for computation per iteration has to be added to the cost for memory access per iteration. Multiplying these costs, as NIST did, is exactly the central mistake highlighted in this blog post.
On the other hand, the estimate comes partially from saying that there's an outer loop increasing the number of iterations compared to Core-SVP. Multiplying the new iteration count by the cost of memory access per iteration makes perfect sense.
Quantifying these effects requires tracing carefully through hundreds of pages of papers on state-of-the-art lattice attacks (not just rewriting the Asiacrypt 2020 paper) to see what would happen if costs of memory access were included.
What makes this really tough is that a change of cost metric also forces reoptimization of the entire stack of attack subroutines, along with all applicable parameters.
Consider, as one of many examples, the choice between low-memory "enumeration" and high-memory "sieving" as a subroutine inside BKZ. The Kyber documentation uses cost metrics that ignore the cost of memory access to conclude that enumeration is less efficient than sieving. If NIST is suddenly saying that memory access makes sieving slower then obviously there's a gap in the Kyber analysis. Where's the recalculation that accounts for the cost of memory access, and for the large recent improvements in enumeration?
Shortly after Matzov's attack appeared in April 2022, I had sent a message to the NISTPQC mailing list summarizing the complicated analysis that needed to be done. I took, as an example, a less Kyber-favorable scenario in which the "known unknowns" reduce 137 to 121, and I said that simply multiplying the bit-operation count by 240 would be wrong:
Does accounting for real RAM costs close the gap between 2121.5 and 2143? One might think that, sure, this is covered by the 240 mentioned above: Kyber-512 previously had security 240*2135.5 = 2175.5, so a 32.5-bit security margin, and the new paper is reducing this to an 18.5-bit security margin: i.e., the new paper is merely cutting out 40% of the Kyber security margin, rather than breaking Kyber outright.
But let's look more closely at the numbers. As a preliminary point, round-3 Kyber-512 is starting from Core-SVP just 2112 and revised-Core-SVP just 2118, with exponent 87% and 91% of 129 respectively, so the obvious estimate is about 236 instead of 240.
Furthermore, this 236 is accounting for the energy cost of accesses to a giant RAM array, while it's clear that many of the bits of security beyond Core-SVP claimed in the round-3 Kyber security analysis are coming from accounting for the cost of local bit operations. These effects don't multiply; they add!
Internally, Core-SVP is starting from estimates of the number of "operations" inside sieving. It makes sense to say that the attacker needs to pay for the large-scale memory access inside each "operation". It also makes sense to say that the attacker needs to pay for all the bit operations inside each "operation". But the local bit operations are an asymptotically irrelevant extra cost on top of the memory access, and the best bet is that they don't make much difference for Kyber-512. The real cost of this type of algorithm is, at a large scale, driven primarily by data motion, not by local computation. ...
So I don't see how current knowledge can justify suggesting that the costs of RAM rescue Kyber-512 from the new attack. It seems entirely possible that the real costs of this Kyber-512 attack are considerably below the costs of a brute-force AES-128 attack. Deciding this one way or the other will require much more serious analysis of attack costs.
An agency desperate to rescue Kyber-512 will take note of the first part of what I had written: great, memory-access costs bump Kyber's security level up by 40 bits, giving us a healthy security margin!
The agency won't listen to the subsequent part saying that, no, this calculation is garbage.
The agency won't even listen to the preliminary adjustment of 40 to 36: we have a healthy security margin, why worry about a few bits here and there?
Meanwhile, if there's something that sounds like a few bits favoring Kyber-512, then the desperate agency happily takes note of that, as the following example illustrates.
The fact that the cost of memory access in each iteration adds to the cost of computation in each iteration, rather than multiplying, has a silver lining for defenders: in the common situation of memory access being dominant, improvements in the cost of computation per iteration make little difference in total cost. I mentioned this in my April 2022 message regarding the Matzov paper:
The new paper seems to have some local speedups to the sieving inner loop, which similarly should be presumed to make little difference next to the memory-access bottleneck, but my understanding is that this is under half of the bits of security loss that the paper is reporting.
Now look at this from the perspective of the desperate agency. Aha, some bits of the Matzov speedup are computation speedups that won't matter next to memory access! As long as we're willing to switch to counting memory access, this effect downgrades the Matzov speedup, which sounds good for Kyber-512!
Sure enough, NISTBS says that "about 5 of the 14 claimed bits of security by Matzov involved speedups to local computations", and portrays this as a "further" reason for confidence in Kyber-512, beyond the "40 bits of additional security" supposedly produced by memory access.
This is double-counting the silver lining. Multiplying the 240 cost of memory access per iteration by Matzov's 2137 bit operations is already assuming (implicitly and incorrectly) that every bit operation has its own iteration, giving 2137 iterations. This leaves no room for multiplying by a "further" 25. The estimated 25 is actually on a completely different axis: it's an estimate for the Matzov-vs.-previous speedup ratio in one metric divided by the Matzov-vs.-previous speedup ratio in another metric.
NIST rescuing Kyber-512, part 3: dodging clarification requests. When NISTBS appeared in December 2022, I looked through and saw that NISTBS was multiplying, rather than adding, the cost of memory access per iteration and the cost of computation per iteration, despite my having already pointed out in April 2022 that this was wrong.
But, hmmm, NIST didn't write NISTBS in a verification-friendly way. In particular, as noted above, NIST didn't include any examples of confirming tallies.
It seemed perfectly clear that NIST was adding "40 bits of additional security" to 137 in scenario X. But NIST didn't bother saying, yes, the security level is 177 in that scenario. NIST also didn't make clear where exactly it was getting the 40 from.
When I find mistakes in security analyses, the authors usually say "Thanks for catching the mistake!"—except in lattice-based cryptography, where the authors usually claim that they meant something different from what they had written. This continual evasion is a serious disincentive to security review. If there was any way that I could have misunderstood what NISTBS was saying, then I wanted to know that at the outset, before doing the work of writing up an explanation of the error.
So I posted a short clarification question. Specifically, I spelled out scenario X and asked whether, in that scenario, I was "correctly gathering that you're calculating the Kyber-512 security level as 2177 (i.e., 34 bits of security margin compared to 2143 for AES-128), where this 177 comes from the above 137 plus 40, where 40 comes from 169 minus 129 on page 103 of the NTRU Prime documentation, specifically 'real' minus 'free' for pre-quantum sieving for sntrup653".
I was expecting a prompt answer saying "Yes, for that specific scenario we're calculating 177 bits of security, and we're getting the 40 from the 169 and 129 that you mentioned."
What actually happened is that NIST didn't reply.
Seriously? NIST picks a risky, bleeding-edge cryptosystem to standardize for users worldwide, and then doesn't even bother answering clarification questions about what NIST claims the security level is?
I mentioned above that I filed a formal complaint regarding the lack of transparency. Here's what the complaint said:
NIST has publicly claimed that Kyber-512 is as difficult to break as AES-128 (see, e.g., page 8 and Figure 1 of NISTIR 8413 claiming that Kyber-512 is "category 1"), at least by known attacks. As you know, this is the minimum security level allowed by the official evaluation criteria for the NIST Post-Quantum Cryptography Standardization Project.
However, NIST has concealed many details of the investigation that led to this claim. NIST admits that "we did consult among ourselves and with the Kyber team"; NIST still has not published those communications.
I have been trying to review the details of NIST's work on this topic. NIST's lack of transparency makes this review process unnecessarily difficult.
Some information was released by Dr. Moody and Dr. Perlner in response to my requests, but this information is (1) incomplete and (2) unclear. My email dated 8 Dec 2022 03:10:06 +0100 consisted of an "am I correctly gathering" clarification question that could have been immediately answered with a simple "Yes, that's correct" if my understanding of NIST's calculations was correct; but there was no reply, so presumably NIST actually meant something else. Surely the communications that NIST is concealing shed light on how NIST actually reached the above claim.
I am writing to file a formal complaint regarding NIST's failure to promptly and publicly disclose full details of its investigation of the security of Kyber-512. This investigation should have been carried out transparently from the outset, allowing prompt correction of any errors that NIST failed to detect. The fact that NIST was still concealing the details in July 2022 prevented the public from seeing how NIST arrived at NISTIR 8413's claims on the topic. The fact that NIST is continuing to conceal the details today seems inexplicable except as part of NIST trying to limit public review of NIST's security evaluations.
Please acknowledge receipt of this message, and please publish full details of NIST's investigation of the security of Kyber-512.
I escalated the complaint to NIST's Matthew Scholl on 20 January 2023. Scholl didn't reply. The public still hasn't seen the details of NIST's consultations "among ourselves and with the Kyber team" regarding Kyber-512.
Maybe Scholl was sending internal email: "Why is djb asking about this? Did we screw something up again?" Maybe NIST looked again at my April 2022 message, realized how badly it had botched its Kyber-512 security analysis, and then decided that it could get away with being obstructionist rather than admitting the error.
Or maybe NIST, still struggling to catch up on post-quantum cryptography, simply hasn't had time to figure out the meaning of the numbers that it's multiplying to obtain its claims regarding Kyber-512. But this doesn't explain what happened next, namely NIST spending more time dodging clarification questions than it would have spent simply answering the questions.
The same day that I escalated my non-transparency complaint to Scholl, I publicly noted NIST's non-responsiveness, and asked if anyone saw another way to interpret NIST's calculations:
In the absence of such clarity, reviewers have to worry that putting NIST's stated components together in what seems to be the obvious way, and then doing the work to disprove what NIST appears to be claiming about the security margin, will lead to a response claiming that, no, NIST meant something else. It's natural to ask for clarification.
... I've again gone through NIST's 7 December email, and again concluded that for this scenario NIST is claiming 34 bits in the way spelled out below. Is there any way I could be missing something here? Does anyone see another way to interpret NIST's calculations?
NIST dodged, replying that NIST's email "speaks for itself".
Well, yes, I think NISTBS speaks for itself, and is very clearly adding the "40 bits of additional security" to the 137 postulated in scenario X, obtaining 177 in that scenario, i.e., 34 bits more than NIST's 143 target. I was simply asking for NIST to confirm that, yes, in that scenario you take the 137 from Matzov, and add the "40 bits of additional security", giving 177 bits of security.
NIST also tried to shift attention to the question of "whether or not our current plan to standardize Kyber512 is a good one", while downplaying the question of whether NIST had correctly calculated the Kyber-512 security level:
While reviewers are free, as a fun exercise, to attempt to "disprove what NIST appears to be claiming about the security margin," the results of this exercise would not be particularly useful to the standardization process.
Seriously? NIST
kicks out NTRU-509 as supposedly being easier to break than AES-128,
keeps Kyber-512 as supposedly being as hard to break as AES-128,
repeatedly, inside its rationale for selecting Kyber, points to Kyber-512's efficiency,
says it's planning to standardize Kyber-512 as supposedly being as hard to break as AES-128, and then
claims that disproving NIST's Kyber-512 security-level calculation wouldn't be useful input?
I replied, starting with again asking for clarification:
I think I understand what NIST is claiming in that message regarding the quantitative Kyber security level.
I think that my clarification question (focusing on one example, much shorter than NIST's message) is identifying the obvious interpretation.
But then why hasn't NIST simply said "Yes, that's correct" in response?
If the interpretation I've identified differs from what NIST meant, can NIST please simply say what the difference is, so that security reviewers don't have to spend time on the quantitative security claims that NIST currently seems to be making?
I also commented on the notion that this wouldn't be useful input:
If Kyber-512 doesn't meet the minimum security level allowed by the official call for submissions to the NIST Post-Quantum Cryptography Standardization Project then Kyber-512 should not be standardized.
NIST's evaluation of the Kyber-512 security level---after various attack advances newer than the latest version of the Kyber submission---depends explicitly on NIST's calculations of the impact of memory costs.
With all due respect, is it so hard to imagine that NIST has botched those calculations? If NIST is so sure that it got the whole sequence of calculations right, why is it so resistant to clarification questions that will help reviewers check and confirm that NIST got this right? If NIST isn't sure, doesn't that make public review even more important?
In any case, there's a strong public interest in having NIST's security evaluations clearly and promptly explained, to maximize the chance of having errors corrected before bad decisions are set into stone.
NIST dodged again:
It would be helpful to redirect discussion to
1) The question of whether Kyber512 is as hard to break as AES128, (which is a scientific question that cannot be settled by NIST pronouncements)
2) The related question of whether Kyber512 should be standardized, (which is a question where NIST will ultimately need to make a definitive decision, but thus far we have only signaled we are leaning towards yes.)
With this in mind, I would like to note that the technical point on which Dan has asked for clarification is effectively "how much additional security does Kyber512 get on account of memory access costs, according to the NTRUprime submission's memory cost model?" Surely Dan, being on the NTRUPrime team, is in a better position to answer this question than us.
Seriously? NIST
takes NTRU Prime's smallest bitops/iter number,
slightly screws up by failing to downscale that number from sntrup653 to Kyber-512,
massively screws up by multiplying that number by Matzov's 2137 bitops,
claims on this basis that "a lot of things would have to go wrong simultaneously to push the real-world classical cost of known attacks against Kyber512 below category 1", and then
says that any questions should be addressed to the NTRU Prime team?
Even if NIST didn't understand by this point that it had screwed up, it certainly knew that
NISTBS was stating conclusions about the Kyber-512 security level relative to AES-128, and
those conclusions were not in the source documents that NISTBS was citing.
Those conclusions were the result of calculations announced by NIST. It's completely inappropriate for NIST to be trying to deflect clarification questions about those calculations.
Chris Peikert had entered the discussion in the meantime to issue blanket denials that NIST was claiming any particular number of bits of security. Of course, Peikert didn't propose an alternative interpretation of NIST's words "40 bits of additional security".
I posted a line-by-line dissection of NISTBS, very similar to the line-by-line dissection shown above, and asked if anyone could see any alternative interpretation:
If anyone sees any way that I could be misunderstanding the details of NIST's posting, please pinpoint which step is at issue and what the alternative interpretation of NIST's calculation is supposed to be.
There was no reply.
Perhaps NIST will now claim that, when it wrote "40 bits of additional security", it actually meant something different from, um, 40 bits of additional security. But then why didn't NIST promptly answer my first question by saying that, no, they didn't mean 40 bits of additional security, and here's what they did mean?
I went far beyond the call of duty in informing NIST of my understanding of NISTBS, asking for confirmation, and giving them ample time to reply. By dodging, NIST successfully delayed having NISTBS publicly debunked.
At some point one has to draw a line and say that this has gone too far. NIST's miscalculation of Kyber-512's security level is still sitting there misinforming people, and it has to be corrected.
NIST rescuing Kyber-512, part 4: standards making unreviewable security claims. In August 2023, NIST released a draft of its Kyber standard ("ML-KEM"), in particular saying "it is claimed that the computational resources needed to break ML-KEM are greater than or equal to the computational resources needed to break the block cipher ... ML-KEM-512 is claimed to be in security category 1, ML-KEM-768 is claimed to be in security category 3, and ML-KEM-1024 is claimed to be in security category 5".
Impressive use of the passive voice. Is NIST claiming these categories? Are the designers claiming these categories? Is someone else claiming these categories?
Citation needed. Or, really, responsibility needed.
Appendix A of the draft again says that these "categories" are defined as matching or surpassing AES-128, AES-192, and AES-256 respectively in every "potentially relevant" cost metric:
Each category is defined by a comparatively easy-to-analyze reference primitive, whose security will serve as a floor for a wide variety of metrics that NIST deems potentially relevant to practical security. ...
In order for a cryptosystem to satisfy one of the above security requirements, any attack must require computational resources comparable to or greater than the stated threshold, with respect to all metrics that NIST deems to be potentially relevant to practical security.
The latest Kyber documentation says that the Kyber-512 attack cost could be as low as 2135 "classical gates". That's below NIST's estimate of 2143 "classical gates" for AES-128, never mind subsequent attack developments. Where exactly is the justification for claiming that Kyber-512 reaches the AES-128 floor in all potentially relevant metrics?
Is NIST now officially declaring that "classical gates" aren't "potentially relevant to practical security"?
If so, how does NIST reconcile this with NIST's 2022 selection report, which used gate counts ("the non-local cost model") as an excuse to kick out the most efficient lattice KEM that NIST was considering, namely NTRU-509?
What exactly are the metrics that NIST is now using for the claim that Kyber-512 is as hard to break as AES-128? When and where were the definitions of those metrics published? (NISTBS doesn't even pass basic type-checking, let alone refer to a clearly defined metric.)
Where's the analysis of Kyber-512's security level in NIST's metrics?
For comparison, where's the analysis of the AES-128 security level in NIST's metrics?
The Kyber documentation concentrates on Kyber-512 for its concrete cost analysis, but the subexponential "dimensions for free" speedup (and subsequent improvements) should do more damage to security at larger sizes. Where are the analyses of the Kyber-768, AES-192, Kyber-1024, and AES-256 security levels in NIST's metrics?
NIST's call for submissions said the following:
All submitters are advised to be somewhat conservative in assigning parameters to a given category, but submitters of algorithms where the complexity of the best known attack has recently decreased significantly, or is otherwise poorly understood, should be especially conservative.
How exactly is this being handled for the latest "category" claims? Are the claims accounting for the 32-bit range of "known unknowns" in the latest Kyber documentation? A wider range given the "unknowns" appearing in newer papers? An even wider range to protect against the likelihood of further attack speedups?
Readers understand the word "claim" to be asserting that something is true, not to be merely saying "we don't think it's terribly likely that this is false". Why does this draft standard conceal NIST's assessment of the probability of failure?
The official NISTPQC call for submissions said "NIST will perform a thorough analysis of the submitted algorithms in a manner that is open and transparent to the public". Scholl said "We operate transparently. We've shown all our work". But the reality is that security reviewers aren't even being given a clear statement of what exactly is being claimed about Kyber's security, let alone what the justification for that claim is supposed to be.
Next steps. Given how unstable and poorly understood the lattice attack surface is, standardizing Kyber-512 (or NTRU-509) would be reckless.
The poor understanding is a sign of danger. Contrary to NISTBS, it's entirely possible that Kyber-512 is substantially easier to break than AES-128 with attacks that have already been published, even considering the costs of memory access. The opposite is also possible. Figuring out the actual status of this bleeding-edge proposal would be a tough research project.
The instability is another sign of danger. How are we supposed to manage the risks of better attacks wiping out many more bits of security?
("Bad news: It's broken. Good news: Comparing it to AES-128 has become much easier.")
AES-128 isn't some stratospheric security level. For example, multi-target attacks against AES-128 take only 288 computations to break one of a trillion keys. That amount of computation is already feasible for large-scale attackers today. Even if you think this is too expensive to worry about, what happens if a cryptosystem actually loses 10 or 20 or 30 bits compared to that?
A paper at ACM CCS 2021 claimed to be able to show that one-out-of-many-ciphertext attacks against Kyber are as hard as single-ciphertext attacks. But I have a paper "Multi-ciphertext security degradation for lattices" that
points out an apparently unfixable flaw in the proof and
shows that, according to the heuristics used in Kyber's security analysis, particular multi-ciphertext attacks are asymptotically more efficient than the standard single-ciphertext attacks.
The main theorem of my paper isn't easy but now has a proof fully verified by HOL Light. "Asymptotically" refers to what happens when sizes grow to infinity; more research is required to quantify the impact of these multi-ciphertext attacks—and whatever improved attacks people find—upon Kyber's limited range of sizes. This is just one of many unexplored parts of the attack surface.
Some attack avenues have clear quantitative limits: for example, 240-target attacks can't eliminate more than 40 bits of security. Replacing Kyber-512 with Kyber-1024 clearly reduces risks (which is not to say that it eliminates all risks: look at what happened to SIKE). There are many previous examples in cryptography of attacks that would have been stopped if cryptographic parameters had been chosen just twice as large as what people had thought was necessary.
Standardizing Kyber-512 means that Kyber-512 will be deployed in many applications that would easily have been able to afford Kyber-1024 or NTRU-1229 or something even larger. This is true even if the standard has Kyber-1024 (or Kyber-768) as an option, even the recommended option. It's easier for a manager to take the fastest option than to investigate whether the fastest option is actually needed. Why exactly won't a manager take the fastest option if NIST has declared it to be a standard option?
Security is supposed to be job #1. So I recommend eliminating Kyber-512. I also recommend that NIST be honest with the public about what happened here:
Honest NIST: "We were desperate to establish that Kyber-512 is as hard to break as AES-128, given the costs of memory access, assuming no attack improvements. This desperation led us to botch our security-level calculations. Sorry."
Public: "So you're withdrawing the claim that Kyber-512 qualifies for category 1?"
Honest NIST: "Correct. We are not making a claim either way. Settling this requires future research. Given the uncertainties regarding the performance of current attacks and the risks of better attacks, we are no longer planning to standardize Kyber-512. Our apologies to anyone who already invested effort in Kyber-512."
Public: "But, wait, doesn't removing Kyber-512 make NTRU the clear winner in flexibility and performance?"
Honest NIST: "Yes. We were desperate to create the opposite perception. That's why we were desperate to keep Kyber-512. That's also why we were manipulating our selection and presentation of data in other ways, for example by kicking out NTRU-509 on the basis of gate counts while keeping Kyber-512 on the basis of memory-access costs. Sorry."
Public: "Partway through the competition, you suddenly started criticizing submissions that weren't providing category 5. NTRU responded with parameters having much higher Core-SVP than Kyber-1024. Does Kyber-1024 meet category 5?"
Honest NIST: "Figuring that out would be another tough research project. The latest versions of Kyber-512, Kyber-768, and Kyber-1024 report Core-SVP 2118, 2183, and 2256, so we extrapolated from saying that Kyber-512 is in category 1 to saying that Kyber-768 is in category 3 and that Kyber-1024 is in category 5. We never looked at the details. Sorry."
Public: "Doesn't your official report say that you're confident in the security of NTRU? Doesn't this mean that NTRU actually scores better than Kyber on all three evaluation factors?"
Honest NIST: "Yes. The only decisive factor listed in our selection report was that Kyber was 'near the top (if not the top) in most benchmarks'. Without Kyber-512, Kyber can't compete with NTRU in performance. Sorry."
Public: "Why were you so desperate to take Kyber over NTRU in the first place?"
Honest NIST: "Here are the full records that we were keeping secret, and in particular they answer that question. These records also show why we weren't meeting our commitment to operate transparently, and why we repeatedly lied about this."
Public: "You exposed three years of user data to attackers by telling people to use Kyber starting when your patent license activates in 2024, rather than telling people to use NTRU starting in 2021!"
Honest NIST: "Sorry. What's done is done. We're locked into standardizing Kyber at this point, and deviating from this would produce even more slowdowns. We'll standardize Kyber-768 as category 2 and Kyber-1024 as category 4."
After everything that has happened, I'm skeptical that we're going to suddenly see Honest NIST, but hope springs eternal.
[2023.10.04 edit: "NIST-509" -> "NTRU-509". 2023.10.05 edits: "than obviously" -> "then obviously"; "40 bits of NTRU Prime" -> "40 bits from NTRU Prime". 2023.10.30 edit: Add Huff reference.]